The Second Ring of AI Investing: Power, Cooling, Data Centers, Custom Chips, and the Real Money Flow
After AI stocks run hard, the market always starts looking outward.
The first ring is obvious.
NVIDIA. Microsoft. OpenAI. Anthropic. Google. Meta. xAI. Amazon.
The second ring is more interesting. GPUs need servers. Servers need data centers. Data centers need power. Power requires interconnection, transformers, backup systems, long-term contracts, and permitting. High-density racks need liquid cooling. AI clusters need HBM memory, advanced packaging, switches, optics, storage, and engineering firms that can actually build the facility.
At that point, AI is no longer just a stock story.
It becomes a payment map.
The better question is not which company has AI exposure. The better question is where the money starts, where it flows, where it gets delayed, and which companies can actually turn announcements into revenue, profit, and cash flow.
This is not a stock-picking guide. It is a map of the second ring of AI infrastructure.
SmartLiving Visual
Interactive AI Second-Ring Map
Click a company to see its layer, relationships, and the risks that matter.
Model and app demand
Frontier model labs and AI apps create the compute demand.
Cloud, GPU cloud, self-built clusters
They turn model demand into deployable, rentable, or internal compute capacity.
GPUs, in-house chips, ASICs
Merchant GPUs, in-house cloud chips, custom ASICs, and networking define compute cost.
Memory, packaging, servers
HBM, advanced packaging, and rack integration turn chips into deployable systems.
Power, cooling, engineering
Without grid access, transformers, liquid cooling, and buildout, GPUs stay on paper.
Start With the Map: The Second Ring Is the Infrastructure Bill
The second ring of AI includes companies that may not build frontier models or sell chatbots, but still capture spending from the AI infrastructure buildout.
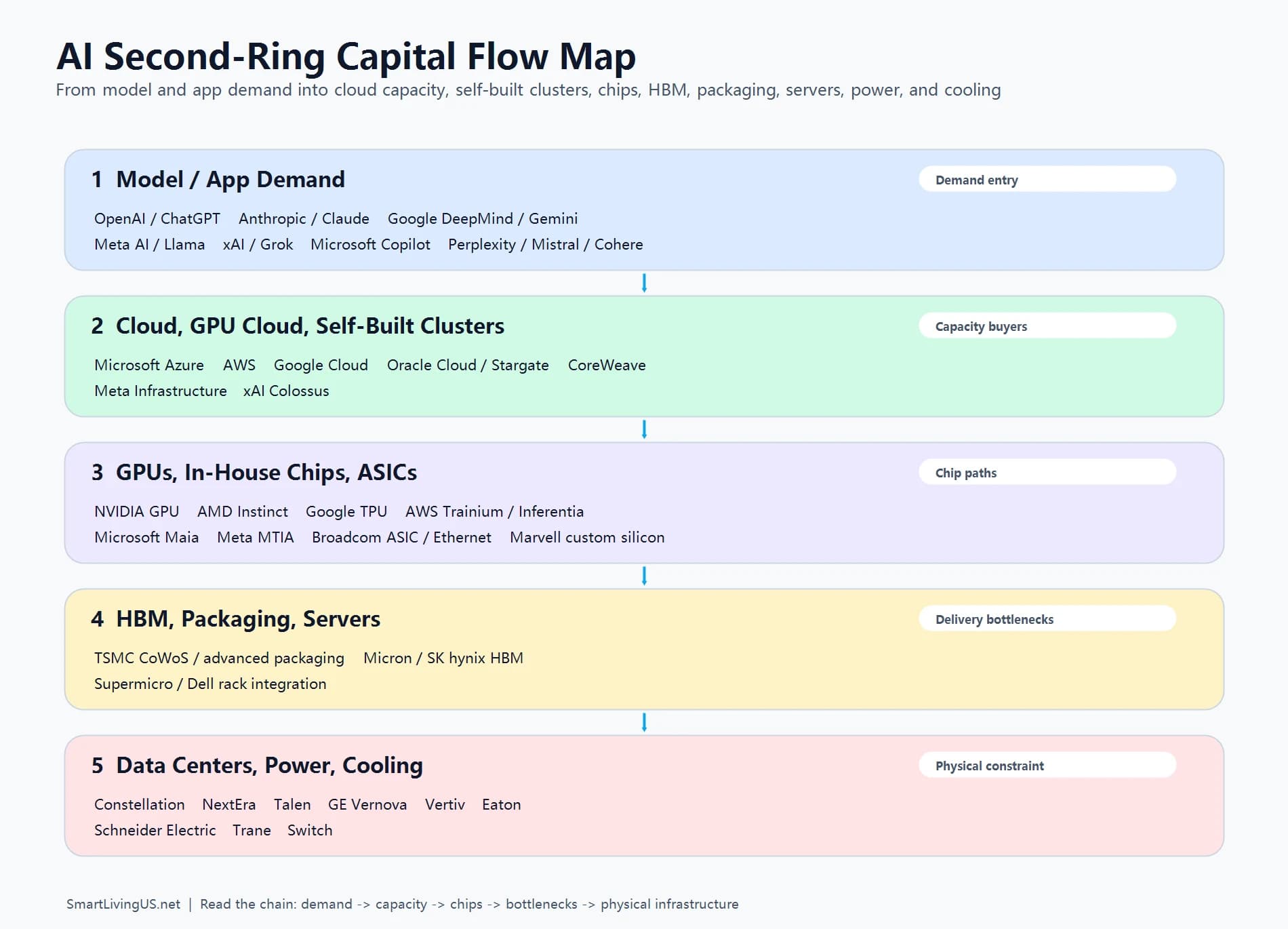
There are five practical layers.
The first layer is model and application demand. OpenAI / ChatGPT, Anthropic / Claude, Google DeepMind / Gemini, Meta AI / Llama, xAI / Grok, and Microsoft Copilot create the training, inference, and enterprise AI demand that pushes into infrastructure.
The second layer is cloud, GPU cloud, and self-built clusters. Microsoft Azure, AWS, Google Cloud, Oracle Cloud, CoreWeave, plus Meta and xAI self-built infrastructure turn demand into rentable, billable, or internal compute capacity.
The third layer is compute hardware. This layer should not stop at NVIDIA, AMD, Broadcom, and Marvell. It also needs Google TPU, AWS Trainium / Inferentia, Microsoft Maia, and Meta MTIA.
The fourth layer is upstream chips and systems. TSMC advanced packaging, Micron and SK hynix HBM, Supermicro and Dell rack-scale integration, and high-performance networking all sit in this layer.
The fifth layer is physical infrastructure. Constellation, NextEra, Talen, GE Vernova, Vertiv, Schneider Electric, Eaton, Trane, Switch, and others solve power, cooling, interconnection, electrical distribution, and facility buildout.
That order matters.
AI money does not fall evenly across the market. It starts with a small group of massive buyers, then moves through contracts, orders, power agreements, reference designs, equipment purchases, and construction timelines.
A company list can tell you who is in the theme.
A payment map tells you how the system works.
Define the First Layer: Model Demand, App Demand, and Cloud Entry Points
This layer is not a headline-company list. It is the entry point where AI demand turns into an infrastructure bill.
Most readers already know ChatGPT, Claude, Gemini, Llama, Grok, and Copilot. The useful question is not whether they exist. The useful question is which infrastructure path each one uses: external cloud, in-house TPU / Trainium / Maia / MTIA chips, self-built clusters, or a company that is simultaneously a model lab, a cloud platform, and an application entry point.
Anthropic is the cleanest example. Anthropic said Amazon’s additional investment makes AWS its primary cloud and training partner, and that Anthropic is working with AWS Annapurna Labs to optimize Trainium accelerators for training and deploying larger Claude models. Source: Anthropic, Powering the next generation of AI development with AWS
Google also cannot be treated only as a cloud layer. Google said Gemini was trained at scale on Google-designed TPU v4 and v5e infrastructure, while Google Cloud’s AI Hypercomputer connects TPUs, data-center networking, software orchestration, and Vertex AI into a training and inference platform. Sources: Google, Introducing Gemini and Google Cloud, Introducing Cloud TPU v5p and AI Hypercomputer
xAI is another demand source that should not be ignored. NVIDIA disclosed that xAI’s Colossus cluster in Memphis used 100,000 NVIDIA Hopper GPUs to train the Grok model family and relied on NVIDIA Spectrum-X Ethernet networking. Source: NVIDIA, xAI Colossus supercomputer
Microsoft is both an infrastructure buyer and an application demand source. Copilot, GitHub Copilot, Office AI, and enterprise AI usage create inference demand, while Azure turns that demand back into GPU clusters and OpenAI-related infrastructure. Microsoft Azure and NVIDIA have disclosed GB300 NVL72 cluster work for OpenAI workloads. Source: Microsoft Azure, NVIDIA GB300 NVL72 for OpenAI workloads
That is why the visual map now treats the first layer as ChatGPT, Claude, Gemini, Llama, Grok, and Copilot demand; the second layer as Azure, AWS, Google Cloud, Oracle, CoreWeave, Meta infrastructure, and xAI Colossus capacity; and the third layer as NVIDIA, AMD, Google TPU, AWS Trainium, Microsoft Maia, Meta MTIA, Broadcom, and Marvell chip paths.
OpenAI Turned AI Capex Into a Gigawatt Story
One reason the second ring has become so important is that OpenAI has started describing compute demand in gigawatts.
In July 2025, OpenAI announced an agreement with Oracle to develop 4.5GW of additional Stargate data center capacity in the United States. OpenAI said that, together with Stargate I in Abilene, the Oracle expansion would bring Stargate AI data center capacity under development to over 5GW and support more than 2 million chips. Source: OpenAI, Stargate advances with 4.5 GW partnership with Oracle
In September 2025, OpenAI, Oracle, and SoftBank announced five additional Stargate data center sites. OpenAI said these sites, along with Abilene and CoreWeave projects, would bring Stargate to nearly 7GW of planned capacity and more than $400 billion of investment over the next three years. Source: OpenAI, Oracle, and SoftBank expand Stargate with five new AI data center sites
Also in September 2025, OpenAI and NVIDIA announced a letter of intent to deploy at least 10GW of NVIDIA systems. NVIDIA said it intended to invest up to $100 billion in OpenAI progressively as each gigawatt is deployed. Source: OpenAI and NVIDIA announce strategic partnership
That last sentence deserves caution.
A letter of intent is not the same as a completed deployment. Planned gigawatts are not the same as powered data centers. These announcements signal direction, demand, and supply-chain pull. They are not today's realized profit.
But they do change the scale of the discussion.
AI infrastructure is no longer only about buying GPUs. It is about power, sites, grid access, cooling, construction, and multi-year capital commitments.
That is the real reason the second ring matters.
The Chip Layer Has Three Paths: Merchant GPUs, In-House Chips, and ASIC / Networking
NVIDIA remains the central compute company in the AI infrastructure stack.
But NVIDIA is no longer just selling chips.
From Hopper to Blackwell to the Vera Rubin platform announced in 2026, NVIDIA is packaging GPUs, CPUs, NVLink, ConnectX, BlueField, Spectrum, rack-scale systems, networking, and data-center reference designs into the AI Factory concept. In March 2026, NVIDIA announced the Vera Rubin DSX AI Factory reference design, with contributors including Eaton, Schneider Electric, Siemens, Switch, Trane Technologies, and Vertiv. Source: NVIDIA Vera Rubin DSX AI Factory reference design
That tells you something important.
NVIDIA wants to define the full AI factory, not only the accelerator.
At the same time, the second ring cannot be reduced to NVIDIA.
In October 2025, OpenAI and Broadcom announced a collaboration to deploy 10GW of OpenAI-designed custom AI accelerators and network systems, with deployment targeted to start in the second half of 2026 and complete by the end of 2029. Source: OpenAI and Broadcom announce strategic collaboration
Meta also expanded its Broadcom relationship in 2026. Meta said it would co-develop multiple generations of MTIA chips with Broadcom to support AI workloads across Meta's apps and services. Source: Meta partners with Broadcom to co-develop custom AI silicon
But if the chip layer only shows NVIDIA, AMD, Broadcom, and Marvell, it is still incomplete.
There are at least three chip paths.
The first path is merchant GPUs and accelerators. NVIDIA remains the center, while AMD Instinct is the most important alternative merchant accelerator line.
The second path is in-house chips from cloud and platform companies: Google TPU, AWS Trainium / Inferentia, Microsoft Maia, and Meta MTIA. Google’s own Gemini materials and Google Cloud TPU materials show the TPU path. AWS Trainium is tightly connected to Anthropic / Claude. Microsoft’s Maia 200 announcement places Maia inside Azure, Microsoft Foundry, Microsoft 365 Copilot, and OpenAI-related workloads. Sources: Microsoft, Maia 200 and AWS Trainium customers
The third path is custom ASIC, networking, and I/O: Broadcom, Marvell, NVIDIA Spectrum-X / InfiniBand, Arista, and related suppliers. They may not replace GPUs directly, but they help define data movement efficiency, inference cost, and customer lock-in.
These three paths belong on the same map.
NVIDIA may remain the dominant general-purpose training and high-end inference platform, but Google TPU, AWS Trainium, Microsoft Maia, Meta MTIA, Broadcom, Marvell, TSMC, HBM suppliers, and networking vendors are now meaningful branches of the AI infrastructure stack.
Custom ASICs do not make GPUs disappear overnight.
They do redirect some AI spending.
HBM and Advanced Packaging Are the Hidden Choke Points
GPUs get the headlines, but AI accelerators cannot run without high-bandwidth memory.
HBM stands for High Bandwidth Memory. Large AI models move enormous amounts of data. Without memory bandwidth, expensive compute sits underused.
In March 2026, Micron announced that its 36GB 12-high HBM4, designed for NVIDIA Vera Rubin, began volume shipment in the first quarter of calendar 2026. Source: Micron HBM4 for NVIDIA Vera Rubin
HBM is still not the whole story.
The GPU die and HBM stacks need advanced packaging. TSMC's CoWoS is a key part of that process. In its 2024 annual report, TSMC discussed strong AI-related demand and listed advanced packaging and 3D stacking technologies such as CoWoS, InFO, and TSMC-SoIC. Source: TSMC 2024 Annual Report
This is why the AI supply chain often looks strange from the outside.
The market talks about GPU shortages, but the actual delay may come from HBM, packaging, substrates, rack integration, or liquid cooling.
One theme. Many bottlenecks.
Data Centers Are Not Buildings. They Are Electrified Financial Assets
People often imagine a data center as a building.
For AI, that is too simple.
An AI data center is an electrified financial asset. It needs land, buildings, transformers, grid interconnection, cooling systems, server racks, long-term customers, and financing.
Oracle's role in Stargate is to connect OpenAI demand with real data-center capacity. CoreWeave represents the more specialized GPU cloud model, turning NVIDIA systems into rentable compute. Traditional data-center REITs such as Equinix and Digital Realty may benefit from capacity demand, but expansion is constrained by power, permits, land, customer contracts, and financing costs.
The key point is this: data-center companies are not necessarily lightweight tech companies.
They are heavy.
Heavy assets mean depreciation, debt, interest rates, lease terms, and utilization matter. Strong AI demand can still become a weak investment if financing costs rise, construction is delayed, or customers are concentrated.
Power Is the Hard Constraint
The International Energy Agency said in its 2026 Energy and AI update that global data center electricity demand grew 17% in 2025 and is projected to roughly double from about 485TWh in 2025 to about 950TWh in 2030, reaching around 3% of global electricity demand. Source: IEA, Key Questions on Energy and AI
That is why nuclear power, natural gas, grids, transformers, and electrical equipment have become part of the AI discussion.
Microsoft signed a 20-year power purchase agreement with Constellation to support the restart of the Crane Clean Energy Center in Pennsylvania, formerly Three Mile Island Unit 1. Source: Constellation, Crane Clean Energy Center announcement
NextEra Energy and Google Cloud announced a strategic energy and technology partnership in December 2025 to scale multiple gigawatts of data center capacity and energy infrastructure across the United States. Source: NextEra Energy and Google Cloud strategic partnership
NVIDIA also announced work with Emerald AI and energy companies including AES, Constellation, Invenergy, NextEra Energy, Nscale Energy & Power, and Vistra to explore AI factories as flexible grid assets. Source: NVIDIA and Emerald AI join energy companies
These announcements point in the same direction.
AI is now an energy-system issue.
But power is not instant. Nuclear restarts require regulatory review. Grid interconnection requires approvals. Transmission takes time. Local communities may object. Equipment lead times can stretch.
Power is an opportunity, and also a timing risk.
Cooling, Electrical Gear, and Rack Integration Are Easy to Underestimate
High-density GPU clusters are not ordinary servers.
They draw more power, produce more heat, and require more complex rack design. Liquid cooling has moved from a niche idea to a central requirement for next-generation AI deployments.
Vertiv announced in 2026 that it was contributing to the NVIDIA Vera Rubin DSX AI Factory reference design and Omniverse DSX Blueprint, including simulation-ready power and cooling assets and repeatable infrastructure blocks. Source: Vertiv on NVIDIA Vera Rubin DSX AI factories
Eaton announced an 800V DC power reference architecture for AI data centers in support of NVIDIA's 800V DC architecture. Source: Eaton 800 VDC architecture for AI factories
Supermicro disclosed NVIDIA Vera Rubin NVL72, HGX Rubin NVL8, and Vera CPU systems, saying its Vera Rubin NVL72 is being engineered with new DCBBS liquid-cooling components to support rack- and cluster-scale power and thermal requirements. Source: Supermicro Vera Rubin NVL72 and liquid cooling
This layer is easy to ignore because it is less glamorous than GPUs.
But it is where chips become usable infrastructure.
No cooling, no uptime.
No electrical design, no AI factory.
Interactive Risk View
AI Second-Ring Interactive Risk Radar
Click a radar point or risk item to see why the second ring is not safer, just more distributed.
How to Read the Contracts
This table is more useful than a company list.
| Relationship | Type | What it says | What to watch | | --- | --- | --- | --- | | OpenAI + Oracle | Data-center capacity agreement | 4.5GW of additional Stargate capacity | Capacity under development is not powered capacity | | OpenAI + NVIDIA | Letter of intent / strategic partnership | At least 10GW of NVIDIA systems, with up to $100B intended NVIDIA investment | A letter of intent is not final deployment | | OpenAI + Broadcom | Custom accelerator collaboration | 10GW of OpenAI-designed accelerators and network systems | Deployment starts later and revenue recognition may lag | | Anthropic + Amazon / AWS | Cloud, investment, and Trainium partnership | Claude training and deployment demand flows into AWS, Trainium, and data-center capacity | Trainium performance, utilization, and contract economics still need proof | | Google / Gemini + TPU / Google Cloud | In-house TPU and cloud infrastructure | Gemini demand connects to TPU, AI Hypercomputer, Vertex AI, and Google Cloud | Some value remains internal to Google and may not spill to public suppliers | | Microsoft + Maia / Azure | In-house inference accelerator | Maia connects Azure, Microsoft Foundry, Copilot, and OpenAI-related workloads | Real deployment scale and performance per dollar still matter | | xAI + NVIDIA | Colossus supercomputer cluster | 100,000 Hopper GPUs and Spectrum-X networking used for Grok models | xAI is private, so financial transparency is limited | | Microsoft Copilot + Azure / OpenAI / NVIDIA | Application demand flows back into cloud infrastructure | Copilot-style apps create inference demand, while Azure supports OpenAI workloads and GPU clusters | Watch whether application revenue covers infrastructure cost | | Meta + Broadcom | Custom silicon collaboration | Multi-generation MTIA development | More inference-oriented; not an immediate GPU replacement | | Microsoft + Constellation | 20-year PPA | Supports Crane Clean Energy Center restart | Nuclear regulation, restart cost, grid timing | | Google Cloud + NextEra | Energy and data-center infrastructure partnership | Multiple GW-scale sites | Permitting, transmission, capex, and regional regulation | | NVIDIA + Vertiv / Schneider / Eaton / Trane | AI Factory reference design ecosystem | Power, cooling, and engineering modules enter NVIDIA's stack | Reference design participation is not equal-sized order capture | | NVIDIA + Supermicro | Rack-scale servers and liquid cooling | Vera Rubin NVL72, HGX Rubin NVL8, DCBBS liquid-cooling components | Delivery quality, margin, inventory, and customer concentration |
The principle is simple.
Announcements are not revenue.
Revenue is not profit.
Profit is not free cash flow.
Free cash flow is not automatically a reasonable valuation.
The most common mistake in second-ring investing is to treat a headline contract as if years of profit have already arrived.
Use Five Questions Before Chasing the Theme
If you research AI infrastructure companies, start with these five questions.
- [ ] Is this company announcing a partnership, receiving an order, delivering equipment, or recognizing revenue?
- [ ] Is customer concentration dangerously high?
- [ ] Does AI demand improve margin, or does it only increase revenue while capex rises too?
- [ ] Does the company need heavy upfront debt or construction spending to capture the opportunity?
- [ ] Has the market already priced in several years of growth?
These questions are more useful than asking whether a company is an AI stock.
Second-ring risk is often not that demand is fake.
It is that demand is slow, expensive, concentrated, and already priced.
How This Connects to Your Existing AI Stock Gains
If you already have gains from AI-related equities, the industry map is only one part of the decision.
Trading fees, short-term versus long-term capital gains, NIIT, New York State tax, and New York City tax can change how much you actually keep. Read this next: The AI Stock Cash-Out Guide: 2026 Trading Fees, Capital Gains Taxes, and the New York Tax Hit
If your focus is buying hardware to run local AI models rather than investing in AI infrastructure companies, this guide is more relevant: 2026 Local AI Hardware Budget Guide: NVIDIA GPU vs High-Memory Mac
The Bottom Line
The second ring of AI is worth studying.
But it is not a safer substitute for the first ring.
It is a longer, heavier, slower capital transmission chain.
GPUs are the brightest part. Power is the hardest constraint. HBM and advanced packaging are hidden choke points. Liquid cooling and rack-scale systems are easy to underestimate.
The smart question is not who the next NVIDIA is.
The smart question is whether you understand the map.
Where does the money start? Which layer receives it? Which companies are only in the headline? Which companies can actually deliver projects into revenue and cash flow?
Only after that does valuation become worth discussing.
Sources
- OpenAI, Stargate advances with 4.5 GW partnership with Oracle
- OpenAI, Oracle, and SoftBank expand Stargate with five new AI data center sites
- OpenAI and NVIDIA announce strategic partnership
- OpenAI and Broadcom announce strategic collaboration
- Anthropic, Powering the next generation of AI development with AWS
- AWS Trainium customers
- Google, Introducing Gemini
- Google Cloud, Introducing Cloud TPU v5p and AI Hypercomputer
- Microsoft, Maia 200
- NVIDIA, xAI Colossus supercomputer
- Microsoft Azure, NVIDIA GB300 NVL72 for OpenAI workloads
- Meta partners with Broadcom to co-develop custom AI silicon
- Micron HBM4 for NVIDIA Vera Rubin
- TSMC 2024 Annual Report
- NVIDIA Vera Rubin DSX AI Factory reference design
- IEA, Key Questions on Energy and AI
- Constellation, Crane Clean Energy Center announcement
- NextEra Energy and Google Cloud strategic partnership
- NVIDIA and Emerald AI join energy companies
- Vertiv on NVIDIA Vera Rubin DSX AI factories
- Eaton 800 VDC architecture for AI factories
- Supermicro Vera Rubin NVL72 and liquid cooling
Disclaimer: This article is for educational and informational purposes only. It is not investment, financial, tax, or legal advice. Company names, partnerships, and official announcements are used only to explain AI infrastructure capital-flow dynamics. They are not recommendations to buy or sell any security, fund, ETF, or industry theme. AI infrastructure investing involves technology, supply-chain, regulatory, financing, valuation, and execution risks. Consult a qualified professional before making investment decisions.
Related Financial Decisions
Keep using the same cash-flow lens on related decisions.
Silver as an Inflation Hedge in 2026: Physical Bullion, SLV-Style ETFs, and PSLV Compared
A practical U.S. investor guide to silver exposure in 2026, covering physical silver premiums, dealer spreads, storage, SLV-style silver ETP costs, collectibles tax treatment, PSLV discounts to NAV, PFIC status, QEF elections, Form 8621, and tax-risk questions to ask before buying.
financeThe AI Stock Cash-Out Guide: 2026 Trading Fees, Capital Gains Taxes, and the New York Tax Hit
A practical after-tax guide for U.S. investors who made money in AI stocks, covering the 2026 SEC Section 31 fee, FINRA TAF, short-term versus long-term capital gains, NIIT, New York State and City taxes, wash sales, 1099-B cost basis, and C-Corp caveats.
financeHELOC vs Cash-Out Refinance in 2026: Should You Tap Home Equity?
Home values are up, but home equity is not free cash. A 2026 guide to comparing HELOCs, home equity loans, and cash-out refinancing through payment shock, tax rules, and household cash flow.
SmartLiving Tools
Keep running the numbers with free practical tools.